Transformer From Scratch#
References#
https://arxiv.org/abs/1706.03762 (Attention is all you need)
https://www.youtube.com/watch?v=eMlx5fFNoYc (3Blue1Brown)
https://sebastianraschka.com/blog/2023/self-attention-from-scratch.html (Sebastian Raschka)
https://www.youtube.com/watch?v=kCc8FmEb1nY (Andrej Karpathy)
https://arxiv.org/pdf/2005.14165 (Language Models are Few-Shot Learners)
https://arxiv.org/abs/1512.03385 (Deep Residual Learning for Image Recognition)
https://arxiv.org/pdf/1607.06450 (Layer Norm)
NishantBaheti/mightypy (Implementation)
https://mightypy.mlguidebook.com/en/latest/api/mightypy.nlp.llm.html (package doc)
Architecture#

[272]:
import numpy as np
import torch
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import math
torch.manual_seed(1)
[272]:
<torch._C.Generator at 0x7d01932c8bf0>
Embedding#
Embeddings are mathematical representation of a word/token with respect to other possible words/tokens. (Idea is to get vector representation of each word with comparable information in a mathematical plane)
We can pick any pretrained embedding model (word2vec, bert etc.) to get word vectors.
I am going to use dummy embeddings for this doc.
Tokenization#
Sentence - I am new to NLP with Deep Learning.
convenient Lie - I|am|new|to|NLP|with|Deep|Learning|. (We’ll be using this for now. Easy to interpret)
Actual Truth - I |am |new to| NLP |with |Deep |Learn|ing. (this is done using BytePairEncoding)
Byte Pair Encoding#
See implementation in C++ here - nishantbaheti/tokkit
Legacy Tokenization#
[273]:
paragraph = """I am new to NLP with deep learning. I like Deep Learning and I like NLP. I am trying to combine it."""
bow = paragraph.lower().replace(".", "").split(" ")
vocab = set(bow)
[274]:
tokenizer = {val: idx for idx, val in enumerate(vocab)}
[275]:
def sentence_separator(sentence):
return sentence.lower().replace(".", "").split(" ")
def get_tokens(sentence):
sentence_sep = sentence_separator(sentence)
tokens = torch.Tensor([tokenizer[i] for i in sentence_sep]).type(torch.int32)
return tokens
def get_embedding(tokens, dim=30):
embed = torch.nn.Embedding(len(vocab), dim)
# detach will make it non learnable parameter and in case of transformers
# it is not needed to have learnable embeddings
# if we are using pretrained models
embedded_sentence = embed(tokens).detach()
return embedded_sentence
[276]:
sentence = "I like NLP"
tokens = get_tokens(sentence)
tokens
[276]:
tensor([3, 1, 6], dtype=torch.int32)
[277]:
X = get_embedding(tokens, dim=10)
[278]:
X
[278]:
tensor([[-0.7981, -0.1316, 1.8793, -0.0721, 0.1578, -0.7735, 0.1991, 0.0457,
0.1530, -0.4757],
[-0.7773, -0.2515, -0.2223, 1.6871, 0.2284, 0.4676, -0.6970, -1.1608,
0.6995, 0.1991],
[ 1.5392, -0.8696, -3.3312, -0.7479, -0.0255, -1.0233, -0.5962, -1.0055,
-0.2106, -0.0075]])
[279]:
X.shape
[279]:
torch.Size([3, 10])
This shape is currently (T, M), but what we would actually need is (B, T, M) where B = Batch, as part of training cycle we’ll have to train it in a batch
[280]:
X.unsqueeze(0).shape
[280]:
torch.Size([1, 3, 10])
Positional Encoding#

As attention is mechanism is designed to work in parallel (as opposed to the older Seq2Seq Model to overcome performance issue) to provide the sense of sequence in input tokens is necessary.
Positional Encoding provides each token a positional aware representation in a sequence
In a sentence This is going to happen anyways . the relationship has to be represented that going is two steps after This and to is one steps after going, this positional awareness/ markers in the sentence has to be infused somehow in the input embeddings of tokens in the sequence.
Each position has a UNIQUE encoding
Compatible with Attention Mechanism
Due to sine and cosine - it is scale invariant
\begin{align*} PE(pos, 2i) &= \sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \\\\ PE(pos, 2i + 1) &= \cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \\\\ \text{where, } pos &= \text{Position of token in sequence} \\ i &= \text{index of dimension} \\ d_{model} &= \text{dimension of model\ embdeding size of the model} \\ \end{align*}
Single value of \(i \in [0, d_{model})\) map both sine and cosine function
values will reside in -1 and 1
10000 is a scaling value
Why sine & cosine ?
Phase difference encoding uniqueness
Linearly independent
due to sine and cosine properties, calculatable that token 5 is closer to token 6 than token 10 without maintaining a sequence,
[281]:
def positional_encoding(n_tokens, d_model, scale=10_000):
"""
* Rows - Positions (sentence length, number of tokens in input sentence)
* Columns - Dimensions (Dimensions of embedding or models)
"""
p = torch.zeros((n_tokens, d_model))
positions = torch.arange(n_tokens)
# for loop approach - just need to run it for half of the dimensions as
for i in range(int(d_model / 2)):
denominator = 1 / math.pow(scale, (2 * i) / d_model)
p[positions, 2 * i] = torch.sin(positions * denominator)
p[positions, (2 * i) + 1] = torch.cos(positions * denominator)
return p
positional_encoding(5, 5)
[281]:
tensor([[ 0.0000, 1.0000, 0.0000, 1.0000, 0.0000],
[ 0.8415, 0.5403, 0.0251, 0.9997, 0.0000],
[ 0.9093, -0.4161, 0.0502, 0.9987, 0.0000],
[ 0.1411, -0.9900, 0.0753, 0.9972, 0.0000],
[-0.7568, -0.6536, 0.1003, 0.9950, 0.0000]])
As for loop is not optimized and pytorch tensor does matrix operations for efficiently so below is the optimized approach
[282]:
def positional_encoding_opt(n_tokens, d_model, scale=10_000):
"""
* Rows - Positions (sentence length, number of tokens in input sentence)
* Columns - Dimensions (Dimensions of embedding or models)
"""
p = torch.zeros((n_tokens, d_model))
positions = torch.arange(n_tokens).unsqueeze(1)
denominator = 1 / torch.pow(scale, torch.arange(0, d_model, 2).unsqueeze(0) / d_model)
if d_model % 2 == 0:
end_idx = denominator.shape[1]
else:
end_idx = denominator.shape[1] - 1
# for even indexes
p[:, 0::2] = torch.sin(positions * denominator)
# for odd indexes
p[:, 1::2] = torch.cos(positions * denominator[:, :end_idx])
return p
positional_encoding_opt(5, 5)
[282]:
tensor([[ 0.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00],
[ 8.4147e-01, 5.4030e-01, 2.5116e-02, 9.9968e-01, 6.3096e-04],
[ 9.0930e-01, -4.1615e-01, 5.0217e-02, 9.9874e-01, 1.2619e-03],
[ 1.4112e-01, -9.8999e-01, 7.5285e-02, 9.9716e-01, 1.8929e-03],
[-7.5680e-01, -6.5364e-01, 1.0031e-01, 9.9496e-01, 2.5238e-03]])
[283]:
pd.DataFrame(
positional_encoding_opt(4, 4, 100),
columns=[f"dim {i}" for i in range(4)],
index=[f"pos {i}" for i in range(4)],
)
[283]:
| dim 0 | dim 1 | dim 2 | dim 3 | |
|---|---|---|---|---|
| pos 0 | 0.000000 | 1.000000 | 0.000000 | 1.000000 |
| pos 1 | 0.841471 | 0.540302 | 0.099833 | 0.995004 |
| pos 2 | 0.909297 | -0.416147 | 0.198669 | 0.980067 |
| pos 3 | 0.141120 | -0.989992 | 0.295520 | 0.955337 |
[284]:
d_model = 40 # M
n_tokens = 10 # T
fig, ax = plt.subplots(2, 1, figsize=(12, 7))
pos_enc = positional_encoding_opt(d_model=d_model, n_tokens=n_tokens, scale=10)
sns.heatmap(
pd.DataFrame(
pos_enc,
columns=[f"dim {i}" for i in range(d_model)],
index=[f"pos {i}" for i in range(n_tokens)],
),
vmin=-1,
vmax=1,
ax=ax[0],
annot=True,
fmt=".1g",
annot_kws={"fontsize": 6}
)
ax[0].set_title("scale 10")
ax[0].set_ylabel("dimensions")
ax[0].set_xlabel("positions")
ax[0].tick_params(labelbottom = False, bottom=False, top = False, labeltop=True)
ax[0].set_xticklabels(ax[0].get_xticklabels(), rotation=90, ha='right')
pos_enc = positional_encoding_opt(d_model=d_model, n_tokens=n_tokens, scale=1000)
sns.heatmap(
pd.DataFrame(
pos_enc,
columns=[f"dim {i}" for i in range(d_model)],
index=[f"pos {i}" for i in range(n_tokens)],
),
vmin=-1,
vmax=1,
ax=ax[1],
annot=True,
fmt=".1g",
annot_kws={"fontsize":6}
)
ax[1].set_title("scale 1000")
ax[1].set_ylabel("dimensions")
ax[1].set_xlabel("positions")
ax[1].tick_params(labelbottom = False, bottom=False, top = False, labeltop=True)
ax[1].set_xticklabels(ax[1].get_xticklabels(), rotation=90, ha='right')
plt.tight_layout()
plt.show()

Here
posis token position anddimembedding dimension, as we would want to map each token’s each dimesion.
[285]:
d_model = 25
n_tokens = 10
pos_enc = positional_encoding_opt(d_model=d_model, n_tokens=n_tokens, scale=100)
fig = plt.figure(figsize=(10, 7))
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, (3, 4))
# individual
for i in range(int(n_tokens/2)):
# For even position
ax1.plot(np.arange(0, d_model, 2), pos_enc[i, 0::2], ".--", label=f"position : {2 * i}")
# For odd position
ax2.plot(
np.arange(1, d_model, 2), pos_enc[i, 1::2], ".--", label=f"position : {2*i + 1}"
)
ax1.legend()
ax1.grid()
ax1.set_title("even dimensions")
ax1.set_xlabel("dimensions")
ax2.legend()
ax2.grid()
ax2.set_title("odd dimensions")
ax2.set_xlabel("dimensions")
# combined
for i in range(int(n_tokens/2)):
# For even position
ax3.plot(np.arange(0, d_model, 2), pos_enc[i, 0::2], ".--", label=f"position : {2 * i}")
# For odd position
ax3.plot(
np.arange(1, d_model, 2), pos_enc[i, 1::2], ".--", label=f"position : {2*i + 1}"
)
ax3.legend(loc="best")
ax3.grid()
ax3.set_title("combined dimensions")
ax3.set_xlabel("dimensions")
plt.tight_layout()
plt.show()

Similarity between position 0 vs 1 and 0 vs 5
[ ]:
(
torch.cosine_similarity(pos_enc[0].view(1, -1), pos_enc[1].view(1, -1)),
torch.cosine_similarity(pos_enc[0].view(1, -1), pos_enc[5].view(1, -1)),
)
(tensor([0.9245]), tensor([0.4458]))
[287]:
(
torch.cosine_similarity(pos_enc[1].view(1, -1), pos_enc[2].view(1, -1)),
torch.cosine_similarity(pos_enc[5].view(1, -1), pos_enc[2].view(1, -1)),
)
[287]:
(tensor([0.9245]), tensor([0.5639]))
[288]:
from sklearn.metrics.pairwise import cosine_distances
sns.heatmap(
pd.DataFrame(
cosine_distances(pos_enc),
),
vmin=0,
vmax=1,
annot=True,
fmt=".1g",
annot_kws={"fontsize":6}
);
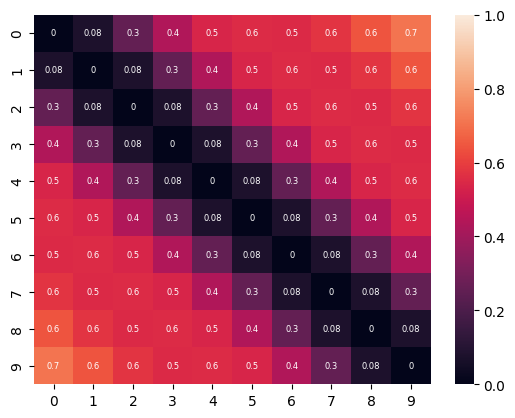
Closer positions have less cosine distance makes it position aware, even it is in parallel
Token Embedding + Positional Encoding#
Intruducing positional awareness to each token’s embedding
[289]:
sentence = "I am new to NLP with deep learning."
tokens = get_tokens(sentence)
[290]:
n_tokens = len(tokens) # T
d_model = 10 # M
pos_enc = positional_encoding_opt(n_tokens=n_tokens, d_model=d_model, scale=100)
df = pd.DataFrame(
pos_enc,
columns=[f"dim {i}" for i in range(pos_enc.shape[1])],
index=[f"pos {i}" for i in range(pos_enc.shape[0])],
)
df.insert(0, column="token", value=tokens)
df.insert(0, column="word", value=sentence_separator(sentence))
df
[290]:
| word | token | dim 0 | dim 1 | dim 2 | dim 3 | dim 4 | dim 5 | dim 6 | dim 7 | dim 8 | dim 9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pos 0 | i | 3 | 0.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 1.000000 |
| pos 1 | am | 11 | 0.841471 | 0.540302 | 0.387674 | 0.921796 | 0.157827 | 0.987467 | 0.063054 | 0.998010 | 0.025116 | 0.999685 |
| pos 2 | new | 0 | 0.909297 | -0.416147 | 0.714713 | 0.699417 | 0.311697 | 0.950181 | 0.125857 | 0.992048 | 0.050217 | 0.998738 |
| pos 3 | to | 9 | 0.141120 | -0.989992 | 0.929966 | 0.367644 | 0.457755 | 0.889079 | 0.188159 | 0.982139 | 0.075285 | 0.997162 |
| pos 4 | nlp | 6 | -0.756802 | -0.653644 | 0.999766 | -0.021631 | 0.592338 | 0.805690 | 0.249712 | 0.968320 | 0.100306 | 0.994957 |
| pos 5 | with | 5 | -0.958924 | 0.283662 | 0.913195 | -0.407523 | 0.712073 | 0.702105 | 0.310272 | 0.950648 | 0.125264 | 0.992123 |
| pos 6 | deep | 8 | -0.279415 | 0.960170 | 0.683794 | -0.729675 | 0.813960 | 0.580922 | 0.369596 | 0.929192 | 0.150143 | 0.988664 |
| pos 7 | learning | 12 | 0.656987 | 0.753902 | 0.347443 | -0.937701 | 0.895443 | 0.445176 | 0.427450 | 0.904039 | 0.174927 | 0.984581 |
[291]:
embeddings = get_embedding(tokens, dim=d_model)
embeddings.shape
[291]:
torch.Size([8, 10])
[292]:
df = pd.DataFrame(
embeddings,
columns=[f"dim {i}" for i in range(embeddings.shape[1])],
index=[f"pos {i}" for i in range(embeddings.shape[0])],
)
df.insert(0, column="token", value=tokens)
df.insert(0, column="word", value=sentence_separator(sentence))
df
[292]:
| word | token | dim 0 | dim 1 | dim 2 | dim 3 | dim 4 | dim 5 | dim 6 | dim 7 | dim 8 | dim 9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pos 0 | i | 3 | -0.389119 | -0.079600 | 0.526932 | 1.619253 | -0.963976 | 0.141520 | -0.163661 | -0.358223 | -0.059444 | -2.491939 |
| pos 1 | am | 11 | -0.587336 | -2.061921 | 0.167477 | 0.751421 | -0.197000 | -0.033396 | 0.719292 | 1.064415 | -0.833572 | -1.192856 |
| pos 2 | new | 0 | 1.511267 | 0.641871 | 0.472964 | -0.428590 | 0.551371 | -1.547371 | 0.757480 | -0.406761 | 0.269241 | 1.324768 |
| pos 3 | to | 9 | 1.724086 | -2.364765 | -0.929491 | 0.293625 | 1.660414 | 0.271740 | 1.465708 | -0.556474 | -0.744841 | -0.202157 |
| pos 4 | nlp | 6 | 0.728246 | 0.057061 | -0.709163 | -0.526246 | -0.520597 | 1.354784 | 0.235193 | 1.914243 | 1.836411 | 1.324532 |
| pos 5 | with | 5 | 0.514916 | -1.847478 | -2.916743 | -0.567330 | -1.199177 | -0.047417 | -0.882507 | 0.531811 | -1.545777 | -0.173300 |
| pos 6 | deep | 8 | -0.271027 | -1.439163 | 1.247040 | 1.273851 | 0.390949 | 0.387210 | 2.641498 | -0.962401 | 0.948827 | -1.383936 |
| pos 7 | learning | 12 | -2.306489 | 0.603657 | 0.315085 | 1.142252 | 0.305506 | -0.578882 | 0.564354 | -0.877328 | -0.269253 | 1.311956 |
Positional Embedding
[293]:
pos_enc.shape, embeddings.shape
[293]:
(torch.Size([8, 10]), torch.Size([8, 10]))
[294]:
pos_enc_emb = pos_enc + embeddings
pos_enc_emb
[294]:
tensor([[-3.8912e-01, 9.2040e-01, 5.2693e-01, 2.6193e+00, -9.6398e-01,
1.1415e+00, -1.6366e-01, 6.4178e-01, -5.9444e-02, -1.4919e+00],
[ 2.5413e-01, -1.5216e+00, 5.5515e-01, 1.6732e+00, -3.9173e-02,
9.5407e-01, 7.8235e-01, 2.0624e+00, -8.0846e-01, -1.9317e-01],
[ 2.4206e+00, 2.2572e-01, 1.1877e+00, 2.7083e-01, 8.6307e-01,
-5.9719e-01, 8.8334e-01, 5.8529e-01, 3.1946e-01, 2.3235e+00],
[ 1.8652e+00, -3.3548e+00, 4.7553e-04, 6.6127e-01, 2.1182e+00,
1.1608e+00, 1.6539e+00, 4.2566e-01, -6.6956e-01, 7.9500e-01],
[-2.8556e-02, -5.9658e-01, 2.9060e-01, -5.4788e-01, 7.1741e-02,
2.1605e+00, 4.8491e-01, 2.8826e+00, 1.9367e+00, 2.3195e+00],
[-4.4401e-01, -1.5638e+00, -2.0035e+00, -9.7485e-01, -4.8710e-01,
6.5469e-01, -5.7224e-01, 1.4825e+00, -1.4205e+00, 8.1882e-01],
[-5.5044e-01, -4.7899e-01, 1.9308e+00, 5.4418e-01, 1.2049e+00,
9.6813e-01, 3.0111e+00, -3.3208e-02, 1.0990e+00, -3.9527e-01],
[-1.6495e+00, 1.3576e+00, 6.6253e-01, 2.0455e-01, 1.2009e+00,
-1.3371e-01, 9.9180e-01, 2.6711e-02, -9.4325e-02, 2.2965e+00]])
[295]:
df = pd.DataFrame(
pos_enc_emb,
columns=[f"dim {i}" for i in range(pos_enc_emb.shape[1])],
index=[f"pos {i}" for i in range(pos_enc_emb.shape[0])],
)
df.insert(0, column="token", value=tokens)
df.insert(0, column="word", value=sentence_separator(sentence))
df
[295]:
| word | token | dim 0 | dim 1 | dim 2 | dim 3 | dim 4 | dim 5 | dim 6 | dim 7 | dim 8 | dim 9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pos 0 | i | 3 | -0.389119 | 0.920400 | 0.526932 | 2.619253 | -0.963976 | 1.141520 | -0.163661 | 0.641777 | -0.059444 | -1.491939 |
| pos 1 | am | 11 | 0.254135 | -1.521618 | 0.555152 | 1.673217 | -0.039173 | 0.954071 | 0.782345 | 2.062425 | -0.808456 | -0.193172 |
| pos 2 | new | 0 | 2.420564 | 0.225724 | 1.187677 | 0.270827 | 0.863068 | -0.597189 | 0.883337 | 0.585288 | 0.319457 | 2.323506 |
| pos 3 | to | 9 | 1.865206 | -3.354758 | 0.000476 | 0.661270 | 2.118168 | 1.160818 | 1.653867 | 0.425664 | -0.669556 | 0.795005 |
| pos 4 | nlp | 6 | -0.028556 | -0.596583 | 0.290603 | -0.547876 | 0.071741 | 2.160474 | 0.484905 | 2.882564 | 1.936718 | 2.319489 |
| pos 5 | with | 5 | -0.444008 | -1.563815 | -2.003547 | -0.974853 | -0.487104 | 0.654688 | -0.572236 | 1.482459 | -1.420513 | 0.818824 |
| pos 6 | deep | 8 | -0.550442 | -0.478992 | 1.930834 | 0.544176 | 1.204909 | 0.968132 | 3.011095 | -0.033208 | 1.098971 | -0.395272 |
| pos 7 | learning | 12 | -1.649502 | 1.357559 | 0.662528 | 0.204551 | 1.200949 | -0.133705 | 0.991804 | 0.026711 | -0.094325 | 2.296538 |
[296]:
pos_enc_emb.shape
[296]:
torch.Size([8, 10])
But in practice the input will be Batch, token, Embedding (B, T, M) + Positional Encoding (1, T, M) = (B, T, M)
[297]:
(pos_enc + embeddings.unsqueeze(0)).shape
[297]:
torch.Size([1, 8, 10])
Scaled Dot-Product Attention (SingleHead)#


It is a communication mechanism (Message Passing for refernce in Graph Theory), where each word passes information/ communicates with other word with some weight.(weighted average/aggregation is passed through the next node from all surrounding nodes and iteratively all the information is aggregates to all the nodes)
It can be understood as a contextual aggregation and a mechanism to understand each word’s importance in given context
\begin{align*} \text{Attention}(Q, K, V) &= \text{softmax}\big( \frac{Q K^T}{\sqrt{d_k}} \big)V \\ \\ Q &= W_Q.X & q_i &= W_Q x_i \text{ where } i \in [1, T] \\ K &= W_K.X & k_i &= W_K x_i \text{ where } i \in [1, T] \\ V &= W_V.X & v_i &= W_V x_i \text{ where } i \in [1, T] \\ \\ \end{align*}
\begin{align*} \text{where } & \\ T &= \text{Number of tokens in the sentence} \\ W_Q, W_K, W_V &= \text{Projection or Learning parameters/weights for query, keys and value vectors} \\ Dimensions &= W_Q (d_k, d_m), W_K (d_k, d_m) ,W_V (d_v, d_m) \\ X, x_i &= \text{Input Embedding for token in a sentence } \\ \\ \text{Where Projection Parameters Represent -} & \\ Q &= \text{What am I looking for ? (What is asked)} \\ K &= \text{What do I have ? (What is given)} \\ V &= \text{What will I get ? (What is important) } \\ \end{align*}
Lets take an example of 2 sentences
I want this to be a fair game
I want to go to a fair
In these sentences word
fairhas two meanings that changes with rest of the context.Below is the visual representation of \(QK^T\) where the multiplication should result in comparably higher value while joining(multiplying) the query and keys vectors (each token gets mulitplied by the whole query) - Information of each token is aggregated to another token, and to calculate the weights it is passed through a softmax layer.
For example -
Query \(\rightarrow\)
I
want
this
to
be
a
fair
game
Keys \(\downarrow\)
I
.
.
.
.
.
.
.
.
want
.
.
.
.
.
.
.
.
this
.
.
.
.
.
.
.
.
to
.
.
.
.
.
.
O
.
be
.
.
.
.
.
.
O
.
a
.
.
.
.
.
.
O
.
fair
.
.
.
O
O
O
O
O
game
.
.
.
.
.
.
O
.
here it roughly represents the weights of
to,be,a,gamefor wordfairis higher than all the other words. This is just a representation of important information in the sentence, that passes through a position encoder to get a sense of sequence as well. Now with position and importance(affinity) it gets a lot of information.
How attention works#
To Understand the need of attention/why attention works, we might need to think about what the input is.
When we are asking auto regressive language model to generate next token, as input we are only providing a chunk of text.
Due to Positional Encoding/Embedding, Model has an awareness of the positions.
Now for if you think about the next possible word for below sentence
We will next ...
It is not grammatically correct as well as it doesn’t have any important information to predict the next word, hence the next word can be anything from city, company to year, month.
Now if I add certain information in the sentence
We will go to India next ...
It is grammatically correct and now with better context we can predict next word with higher probability like year, month.
Now if you have reached to the same conclusion, you’d think how your mind processed this information.
You got a sentence, you figured out main/primary contexts/words with higher weightage( go, India) and some supporting words. Using both of these insights, the next word came to you based on your knowledge of general English, that you have attained over time.
[298]:
d_model = 30
sentence = "I like learning NLP"
tokens = get_tokens(sentence)
X = get_embedding(tokens, dim=d_model)
Linear Transformation (Projection)#
Two schools of thought
As the embeddings of tokens are from a separate model/vector space. (If we are using pretrained embeddings), To integrate the embeddings in the transformers vector space we need some projection vectors that belong to this architecture.
We are going to need learnable parameters so that we can introduce linear transformations of embeddings, kind of augmenting the inputs in various dimensions and still getting the same results in most chances.
\(d_{key} = d_{query} = d_k\) as the final result has to be a square matrix. each token with information aggregated from each token
[299]:
d_k = 24
d_value = 30
W_Q = torch.rand(d_k, d_model, requires_grad=True) * 1e-1
W_K = torch.rand(d_k, d_model, requires_grad=True) * 1e-1
W_V = torch.rand(d_value, d_model, requires_grad=True) * 1e-1
[300]:
Q = torch.matmul(X, W_Q.T)
# alternatively
# W_Q = torch.nn.Linear(d_model, bias=False)
# Q = W_Q(X)
K = torch.matmul(X, W_K.T)
V = torch.matmul(X, W_V.T)
Q.shape, K.shape, V.shape
[300]:
(torch.Size([4, 24]), torch.Size([4, 24]), torch.Size([4, 30]))
Q . K (dot product)#
Why dot product, to understand this first we need to understand matrix multiplication (https://mlguidebook.com/en/latest/MathExploration/matrix_multiplication.html)
Here every word will talk to each other, and the embedding dimesions are multiplied (Contextual Aggergation).
\begin{align*} Q (T, M) \begin{bmatrix} q_{1,1} & q_{1,2} & \dots & q_{1,M}\\ q_{2,1} & q_{2,2} & \dots & q_{2,M}\\ & & .\\ & & .\\ q_{T,1} & q_{T,2} & \dots & q_{T,M} \end{bmatrix} \times K^T (M, T) \begin{bmatrix} k^T_{1,1} & k^T_{1,2} & \dots & k^T_{1,T}\\ k^T_{2,1} & k^T_{2,2} & \dots & k^T_{2,T}\\ & & .\\ & & .\\ k^T_{M,1} & k^T_{M,2} & \dots & k^T_{M,T} \end{bmatrix} = \\ \\ (T, T) \begin{bmatrix} (q_{1,1} \times k^T_{1,1}) + (q_{1,2} \times k^T_{2,1}) + \dots + (q_{1,M} \times k^T_{M,1}) & \dots & \\ . & \\ . & \\ \end{bmatrix} \end{align*}
This dot product provides a (T, T) matrix where it shows relation of each token with rest of the tokens.
[301]:
omega = Q @ K.T
sns.heatmap(pd.DataFrame(
torch.round(omega, decimals=2).detach().numpy(),
columns=sentence_separator(sentence),
index=sentence_separator(sentence),
), annot=True, annot_kws={"size" : 8}) ;
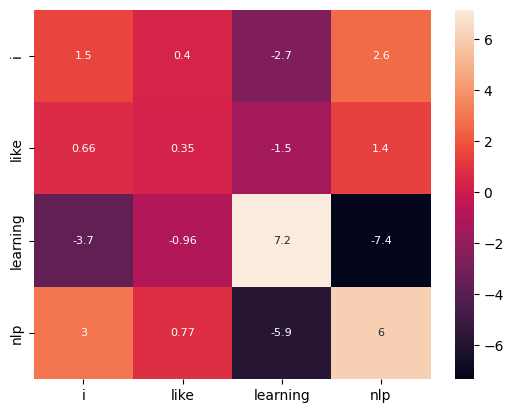
Softmax (Context to weight)#
from dot product we get contextual aggregation for each token, to figure out each token’s weight(importance) we need a method to convert logits/matrix to weights/probability in a manner that during backpropagation the learnable parameters are trained based on backpropagation of the softmax loss.
take below example of softmax learning
\begin{align*} \begin{bmatrix} w_{1,1} & w_{1,2} & \dots & w_{1,T} \end{bmatrix} \rightarrow softmax(\begin{bmatrix} w_{1,1} & w_{1,2} & \dots & w_{1,T} \end{bmatrix}) \rightarrow \begin{bmatrix} 0 & 1 & & \dots & 0 \end{bmatrix} \end{align*}
At the time of backpropagation the parameters with try to reach closer to the values of true value with iterations using probabilities.
[302]:
def softmax(x):
if len(x.shape) == 1:
x = x.view(1, -1)
return torch.exp(x) / torch.sum(torch.exp(x), dim=1).view(-1, 1)
softmax(torch.Tensor([1, 1, 1, 1])), softmax(torch.Tensor([[1, 1, 1, -1], [1, 2, 1, 4]]))
[302]:
(tensor([[0.2500, 0.2500, 0.2500, 0.2500]]),
tensor([[0.3189, 0.3189, 0.3189, 0.0432],
[0.0403, 0.1096, 0.0403, 0.8098]]))
[303]:
omega = softmax((Q @ K.T) / math.sqrt(d_k))
sns.heatmap(pd.DataFrame(
torch.round(omega, decimals=2).detach().numpy(),
columns=sentence_separator(sentence),
index=sentence_separator(sentence),
), annot=True, annot_kws={"size" : 8}) ;
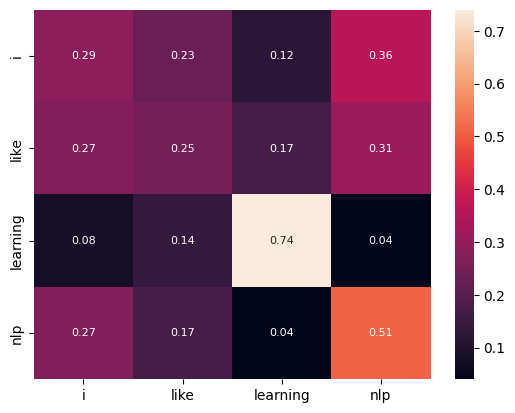
Why Scaling?#
dividing by \(\sqrt{d_k}\)
[304]:
Q @ K.T
[304]:
tensor([[ 1.5191, 0.4029, -2.6699, 2.6404],
[ 0.6569, 0.3494, -1.4591, 1.3661],
[-3.6791, -0.9588, 7.1673, -7.3582],
[ 2.9663, 0.7670, -5.8728, 6.0410]], grad_fn=<MmBackward0>)
Here the value of last cell has become very big and if this matrix is passed through softmax then it will become a one-hot vector, instead of fairly diffused vector
[305]:
softmax(Q @ K.T)
[305]:
tensor([[2.2668e-01, 7.4243e-02, 3.4367e-03, 6.9564e-01],
[2.5719e-01, 1.8911e-01, 3.0994e-02, 5.2271e-01],
[1.9468e-05, 2.9563e-04, 9.9968e-01, 4.9148e-07],
[4.3948e-02, 4.8733e-03, 6.3705e-06, 9.5117e-01]],
grad_fn=<DivBackward0>)
Now if we scale it with the value
[306]:
(Q @ K.T) / math.sqrt(d_k)
[306]:
tensor([[ 0.3101, 0.0822, -0.5450, 0.5390],
[ 0.1341, 0.0713, -0.2978, 0.2789],
[-0.7510, -0.1957, 1.4630, -1.5020],
[ 0.6055, 0.1566, -1.1988, 1.2331]], grad_fn=<DivBackward0>)
[307]:
softmax((Q @ K.T) / math.sqrt(d_k))
[307]:
tensor([[0.2875, 0.2289, 0.1222, 0.3614],
[0.2671, 0.2508, 0.1734, 0.3087],
[0.0809, 0.1409, 0.7401, 0.0382],
[0.2720, 0.1736, 0.0448, 0.5096]], grad_fn=<DivBackward0>)
Now whole purpose of softmax is provide weights to each token and aggregate the results in value, but if there are sharp/high values in dot product resulting in one-hot encoded softmax weights then we are just taking value from one token while ignoring the other. and these extreme cases will be very frequent.
Attention#
Multiplying weights with the values
[308]:
def attention(Q, K, V, d_k):
omega = softmax((Q @ K.T) / np.sqrt(d_k))
return omega @ V
[309]:
attn_out = attention(Q, K, V, d_k)
attn_out.shape
[309]:
torch.Size([4, 30])
[310]:
df = pd.DataFrame(
attn_out.detach().numpy(),
columns=[f"dim {i}" for i in range(attn_out.shape[1])],
index=sentence_separator(sentence),
)
df
[310]:
| dim 0 | dim 1 | dim 2 | dim 3 | dim 4 | dim 5 | dim 6 | dim 7 | dim 8 | dim 9 | ... | dim 20 | dim 21 | dim 22 | dim 23 | dim 24 | dim 25 | dim 26 | dim 27 | dim 28 | dim 29 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| i | -0.284423 | -0.217087 | -0.149338 | -0.183346 | -0.248697 | -0.196229 | -0.274385 | -0.231844 | -0.198607 | -0.192838 | ... | -0.307231 | -0.209696 | -0.110503 | -0.207584 | -0.110770 | -0.276080 | -0.272785 | -0.192349 | -0.114457 | -0.177243 |
| like | -0.214163 | -0.175120 | -0.097939 | -0.127474 | -0.192384 | -0.134956 | -0.205493 | -0.166487 | -0.137500 | -0.125896 | ... | -0.240469 | -0.180047 | -0.071341 | -0.170373 | -0.043438 | -0.206784 | -0.208458 | -0.153011 | -0.057064 | -0.120934 |
| learning | 0.450952 | 0.200131 | 0.395280 | 0.252659 | 0.300613 | 0.460472 | 0.415876 | 0.312267 | 0.461009 | 0.420485 | ... | 0.398716 | 0.165281 | 0.384013 | 0.194670 | 0.501211 | 0.395726 | 0.376946 | 0.272277 | 0.428739 | 0.318302 |
| nlp | -0.399717 | -0.303272 | -0.237257 | -0.307312 | -0.346824 | -0.290766 | -0.412380 | -0.384135 | -0.311943 | -0.326566 | ... | -0.424717 | -0.253907 | -0.181674 | -0.286957 | -0.237407 | -0.393159 | -0.387088 | -0.255444 | -0.223930 | -0.301350 |
4 rows × 30 columns
Embedding + Positional Encoding + Attention#
[311]:
d_model = 10
sentence = "I like NLP with deep learning."
tokens = get_tokens(sentence)
n_tokens = len(tokens)
embeddings = get_embedding(tokens, dim=d_model)
embeddings.shape
[311]:
torch.Size([6, 10])
[312]:
pos_enc = positional_encoding_opt(n_tokens=n_tokens, d_model=d_model, scale=100)
d_k, d_k, d_value = 10, 10, d_model
W_Q = torch.rand(d_k, d_model, requires_grad=True) * 1e-1
W_K = torch.rand(d_k, d_model, requires_grad=True) * 1e-1
W_V = torch.rand(d_value, d_model, requires_grad=True) * 1e-1
[313]:
pos_emb = pos_enc + embeddings
[314]:
Q = torch.matmul(pos_emb, W_Q.T)
K = torch.matmul(pos_emb, W_K.T)
V = torch.matmul(pos_emb, W_V.T)
attn_out = attention(Q, K, V, d_k)
df = pd.DataFrame(
attn_out.detach().numpy(),
columns=[f"dim {i}" for i in range(attn_out.shape[1])],
index=[f"pos {i}" for i in range(attn_out.shape[0])],
)
df.insert(
loc=0,
column="word",
value=sentence_separator(sentence),
)
df
[314]:
| word | dim 0 | dim 1 | dim 2 | dim 3 | dim 4 | dim 5 | dim 6 | dim 7 | dim 8 | dim 9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| pos 0 | i | 0.304304 | 0.243358 | 0.296470 | 0.284065 | 0.285642 | 0.380301 | 0.334510 | 0.372676 | 0.140875 | 0.232712 |
| pos 1 | like | 0.290174 | 0.230760 | 0.278115 | 0.275119 | 0.273675 | 0.366807 | 0.315616 | 0.353479 | 0.131922 | 0.225117 |
| pos 2 | nlp | 0.284779 | 0.226066 | 0.271892 | 0.271595 | 0.269654 | 0.362032 | 0.309284 | 0.346826 | 0.128665 | 0.222290 |
| pos 3 | with | 0.299592 | 0.239619 | 0.291136 | 0.281260 | 0.282335 | 0.376334 | 0.329172 | 0.367241 | 0.138155 | 0.230564 |
| pos 4 | deep | 0.310730 | 0.249186 | 0.305428 | 0.288055 | 0.291562 | 0.386709 | 0.343992 | 0.381982 | 0.145033 | 0.236227 |
| pos 5 | learning | 0.302413 | 0.242086 | 0.293683 | 0.283271 | 0.284114 | 0.378466 | 0.332307 | 0.370339 | 0.139613 | 0.232057 |
MultiHead Attention#
Now the one attention can run in multiple heads parallelly to generative different transformations.
\begin{align*} \text{Multihead}(Q, K, V) &= \text{Concat}(head_1, head_2, ... , head_h) W^o \\\\ \text{where } head_i &= \text{Attention}(QW_i^Q,KW_i^K,VW_i^V) \\ W^o &= \text{Output projection }, Dimensions = (d_m, d_v * n_{heads}) \end{align*}
Once we understand how attention works, what if we get multiple attention heads (all different transformations), concat the heads and project them to a combined outcome using Output Projection (\(W^o\)), so that even after multiple different transformations we should be getting the similar weight ratios in most of the heads for the given input.
This step ensures an ensemble of opinios of multiple attention heads and their learnable parameters.
[315]:
d_model = 100
n_heads = 3
sentence = "I like NLP with deep learning."
tokens = get_tokens(sentence)
X = get_embedding(tokens, dim=d_model)
X_repeat = X.repeat(n_heads, 1, 1)
X.shape, X_repeat.shape
[315]:
(torch.Size([6, 100]), torch.Size([3, 6, 100]))
[316]:
d_k, d_value = 28, 30
W_Q = torch.rand(n_heads, d_k, d_model, requires_grad=True) * 1e-1
W_K = torch.rand(n_heads, d_k, d_model, requires_grad=True) * 1e-1
W_V = torch.rand(n_heads, d_value, d_model, requires_grad=True) * 1e-1
[317]:
W_O = torch.rand(d_model, n_heads * d_value, requires_grad=True) * 1e-1
[318]:
X.shape, W_Q.shape
[318]:
(torch.Size([6, 100]), torch.Size([3, 28, 100]))
[319]:
Q = torch.bmm(X_repeat, W_Q.transpose(-2, -1)) # Transposing last two dimensions (leaving heads)
K = torch.bmm(X_repeat, W_K.transpose(-2, -1))
V = torch.bmm(X_repeat, W_V.transpose(-2, -1))
Q.shape, K.shape, V.shape
[319]:
(torch.Size([3, 6, 28]), torch.Size([3, 6, 28]), torch.Size([3, 6, 30]))
[320]:
def multihead_softmax(x):
return torch.exp(x)/ torch.exp(x).sum(dim=-1, keepdim=True)
def multihead_attention(Q, K, V, W_O, d_k):
omega = (Q @ K.transpose(-2, -1)) / math.sqrt(d_k)
attn_out_int = multihead_softmax(omega) @ V
print("Intermediate Shape ", attn_out_int.shape, "-> ", end="")
H, T, M = attn_out_int.shape
# below operation in same sequence is important to reshape and project
attn_out_int = attn_out_int.permute(1, 0, 2).reshape(T, H * M)
print(attn_out_int.shape)
print(attn_out_int.shape , "x", W_O.T.shape)
return attn_out_int @ W_O.T
[321]:
attn_out = multihead_attention(Q, K, V, W_O, d_k)
attn_out.shape
Intermediate Shape torch.Size([3, 6, 30]) -> torch.Size([6, 90])
torch.Size([6, 90]) x torch.Size([90, 100])
[321]:
torch.Size([6, 100])
[322]:
attn_out.shape == X.shape
[322]:
True
Now the output Multihead attention is same as input X, This is by design and helps in couple of ways
Later we will’be reading about Repeat Block, This Repeat Block is a Block
[Masked Multi Head Attention, Multi Head Attention, FFN]that is repeat N number of times, so It is easy to manange the same size of input and output so the block can be repeated without introducing additional layer to reshape.As we understand the input is (Batch, tokens, Model Dimension) which represents each token from the input prompt and the context via the model dimension now with every repeated block what we are trying to ingect is the understanding(positional awareness + attention) of the prompt deeper and deeper.
Pytorch Efficient Way#
Implementation Above is very close to the paper.
But it is not an efficient way to implement in pytorch or tensorflow.
So there no conceptual change, programmatical change will be changing W_Q, W_K, W_V and W_O to Linear Layers without bias and instead of repeating the input X number of heads time, change the input units of each of these learning parameters (Multiply with number of heads). It means that we are imagining multiple heads but doing all the opeations in single head with multiple processing nodes, Helps GPU to process things faster.
Once the dot product is completed then reshape the values to original interpretion. See implementation below
We are doing it for one prompt hence there no batch dimension
[323]:
d_model = 100
n_heads = 3
sentence = "I like NLP with deep learning."
tokens = get_tokens(sentence)
X = get_embedding(tokens, dim=d_model)
# no need to repeat the X number of heads time
X.shape
[323]:
torch.Size([6, 100])
[324]:
B, (T, M )= 1, X.shape
[325]:
d_k, d_v = 28, 30
W_Q = torch.nn.Linear(d_model, d_k * n_heads, bias=False) # torch.rand(n_heads, d_k, d_model, requires_grad=True) * 1e-1
W_K = torch.nn.Linear(d_model, d_k * n_heads, bias=False) # torch.rand(n_heads, d_k, d_model, requires_grad=True) * 1e-1
W_V = torch.nn.Linear(d_model, d_v * n_heads, bias=False) # torch.rand(n_heads, d_v, d_model, requires_grad=True) * 1e-1
[326]:
W_O = torch.nn.Linear(n_heads * d_value,d_model, bias=False)
[327]:
Q = W_Q(X).view(T, n_heads, d_k).transpose(0, 1) # torch.bmm(X_repeat, W_Q.transpose(-2, -1)) # Transposing last two dimensions (leaving heads)
K = W_K(X).view(T, n_heads, d_k).transpose(0, 1) # torch.bmm(X_repeat, W_K.transpose(-2, -1))
V = W_V(X).view(T, n_heads, d_v).transpose(0, 1) # torch.bmm(X_repeat, W_V.transpose(-2, -1))
Q.shape, K.shape, V.shape
[327]:
(torch.Size([3, 6, 28]), torch.Size([3, 6, 28]), torch.Size([3, 6, 30]))
[328]:
def multihead_softmax(x):
return torch.exp(x)/ torch.exp(x).sum(dim=-1, keepdim=True)
def multihead_attention(Q, K, V, W_O, d_k):
omega = (Q @ K.transpose(-2, -1)) / math.sqrt(d_k)
print(omega.shape)
attn_out_int = multihead_softmax(omega) @ V
print("Intermediate Shape ", attn_out_int.shape, "-> ", end="")
H, T, M = attn_out_int.shape
# below operation in same sequence is important to reshape and project
attn_out_int = attn_out_int.permute(1, 0, 2).reshape(T, H * M)
print(attn_out_int.shape)
return W_O(attn_out_int)
[329]:
attn_out = multihead_attention(Q, K, V, W_O, d_k)
attn_out.shape
torch.Size([3, 6, 6])
Intermediate Shape torch.Size([3, 6, 30]) -> torch.Size([6, 90])
[329]:
torch.Size([6, 100])
[330]:
attn_out.shape == X.shape
[330]:
True
Masked-MultiHead Attention (Optional)#
mask the tokens that come in next steps (as -inf)
so that softmax converts them to zero
In cases of chatbot, the algorithm should not know the next word at the time of training
so that it can predict the probability of next word based on target values and hadn’t seen the value before
This is an optional step where word prediction/generation is the use case, Hence it can be ignored for the use cases like Language Translation, Sentiment Analysis etc., where we need the whole sentence and each token to talk to each other
Create a mask where the next word in sequence cannot communicate the previous token, mathematic before passing it to softmax next token variable in sequence are converted to -inf (\(-\infty\)) because \(e^{-\infty} = 0\)
[331]:
math.exp(-math.inf)
[331]:
0.0
[332]:
# for example there are 5 tokens in the input sentence
M = torch.rand((5, 5))
M
[332]:
tensor([[0.2317, 0.8151, 0.0131, 0.9078, 0.7616],
[0.4272, 0.8797, 0.5416, 0.9425, 0.0079],
[0.4262, 0.5897, 0.5218, 0.3691, 0.1845],
[0.4828, 0.5351, 0.6572, 0.8700, 0.0808],
[0.0856, 0.0563, 0.6690, 0.2299, 0.4037]])
[333]:
M[torch.tril(M) == 0 ] = float("-inf")
M
# M.masked_fill(torch.tril(M) == 0, float("-inf"))
[333]:
tensor([[0.2317, -inf, -inf, -inf, -inf],
[0.4272, 0.8797, -inf, -inf, -inf],
[0.4262, 0.5897, 0.5218, -inf, -inf],
[0.4828, 0.5351, 0.6572, 0.8700, -inf],
[0.0856, 0.0563, 0.6690, 0.2299, 0.4037]])
[334]:
masked_softmax = softmax(M)
sns.heatmap(masked_softmax, annot=True)
[334]:
<Axes: >
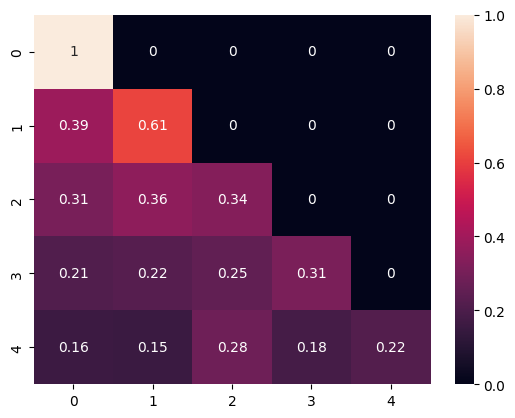
[335]:
def multihead_attention(Q, K, V, W_O, d_k, masked=False):
omega = (Q @ K.transpose(-2, -1)) / math.sqrt(d_k)
if masked:
omega = omega.masked_fill(torch.tril(omega) == 0, float("-inf"))
attn_out_int = multihead_softmax(omega) @ V
print("Intermediate Shape ", attn_out_int.shape, "-> ", end="")
H, T, M = attn_out_int.shape
# below operation in same sequence is important to reshape and project
attn_out_int = attn_out_int.permute(1, 0, 2).reshape(T, H * M)
print(attn_out_int.shape)
return W_O(attn_out_int)
Masked Softmax#
[336]:
omega = Q @ K.transpose(-2, -1) / math.sqrt(d_k)
omega = omega.masked_fill(torch.tril(omega) == 0, float("-inf"))
fig, ax = plt.subplots(1, 2, figsize=(7, 3))
sns.heatmap(multihead_softmax(omega)[0].detach().numpy(), annot=True, ax=ax[0], annot_kws={"size": 8})
sns.heatmap(multihead_softmax(omega)[1].detach().numpy(), annot=True, ax=ax[1], annot_kws={"size": 8})
fig.show()
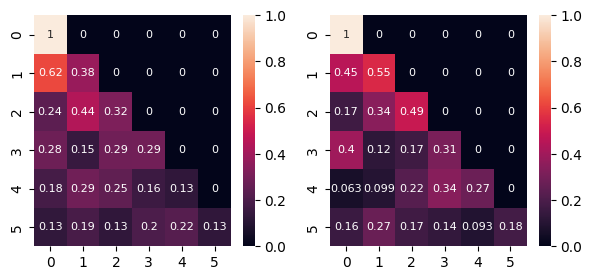
Now only previous words/affinity will give context to the current tokens
[337]:
masked_attn_out = multihead_attention(Q, K, V, W_O, d_k, masked=True)
masked_attn_out.shape
Intermediate Shape torch.Size([3, 6, 30]) -> torch.Size([6, 90])
[337]:
torch.Size([6, 100])
Self Attention Vs Cross Attention#
Attention supports both masked and non-masked multihead attention as it provides the fecility to Self-Attention & Cross-Attention.
When Query, Key and Value all are from Same Source then It is called Self-Attention.
Where Query is from One Source and Key, Value are from Another Source then it is called Cross-Attention.
Add & Norm (Convergence Optimizations)#

Skip Connections (Add)#
In skip connections a copy of input is added with the output of the set of calculations.
In this particular example input embeddings are added with the results of Multi-Head Attention.
Input (X)
|
|
o Fork
| \
| | \ A
| | \ |
| | | |
| | |-----------| |
| | | Multi | | Backward
Forward | | | | | |
| | | Head | |
| | | | | |
V | | Attention |
| |-----------|
| |
| /
| /
| /
addition
|
|
Output (X)
Because of skip connection the gradients can travel faster to initial layers and initial layers can learn as fast as final layers, This helps when we are building very Deep Neural Networks
[338]:
X.shape, masked_attn_out.shape
[338]:
(torch.Size([6, 100]), torch.Size([6, 100]))
[339]:
add_x = X + masked_attn_out
add_x.shape
[339]:
torch.Size([6, 100])
Layer Normalization#
\begin{align*} y_i &= \frac{x_i - \mu}{\sqrt{ \sigma^2 - \epsilon}}. \gamma + \beta \\\\ \text{where } \\ \mu &= \text{mean} \\ \sigma^2 &= \text{variance} \\ \epsilon &= \text{constant for numerical stability} \\ \gamma &= \text{learnable parameter for rescale, initialized with 1} = \frac{\delta L}{\delta \gamma} \\ \beta &= \text{learnable parameter for reshift, initialized with 0} = \frac{\delta L}{\delta \beta} \end{align*}
This is row-wise normalization, which is different from batch normalization, which makes it independent from batch size.
Normalization makes it better for convergence, and better generalization.
Consider all tokens/rows with different different distribution with same distribution type, It would be optimum to converege if we all the tokens dimensions are normalized.
[340]:
layer_norm = torch.nn.LayerNorm(add_x.shape[-1])
[341]:
norm_out = layer_norm(add_x)
norm_out.shape
[341]:
torch.Size([6, 100])
[342]:
fig, ax = plt.subplots(1, 1, figsize=(4, 4))
# fade bars
sns.histplot(add_x[0, :].detach().numpy(), bins=20, ax=ax, kde=True, color='blue', label='add_x' )
sns.histplot(norm_out[0, :].detach().numpy(), bins=20, ax=ax, kde=True, color='red', label='add_and_normalized_out')
ax.legend()
fig.show();

This shows before and after the normalization the distribution is slightly more normal
Position-Wise Feed Forward Network#

After Attention block each token from each head is connected separately to a fully connected feed forward network
As attention block helps the network understand the importance(Attention) of each word in given context. We still need a mechanism to put it to good use.
Position-Wise Feed Forward Network helps by using the learned importance to localize in a network to build better semantic relationships using word importance.
According to the paper it is two dense layers with ReLU Activation function.
- :nbsphinx-math:`begin{align*}
FFN(x) &= max(0, W_1 X + k^T_1). W_2 + b_2
end{align*}`
[343]:
X = torch.nn.Linear(d_model, 3 * d_model, bias=True)(X)
X = torch.nn.ReLU()(X)
X = torch.nn.Linear(3 * d_model, d_model, bias=True)(X)
Repeated Block#
[ Masked Multihead Attention + Attention + FFN ] is considered a block and this block does two things (Reiterating).
Learn importance of each token for given context (Contextual Aggregation)
Learn semantic relationship of each token independently with relation to other tokens
This Block is repeated N number of times to get more refined understanding.
Pytorch provides a method
ModuleListto integrate modules given in a list (iterable).
[344]:
class DummyRepeatBlock(torch.nn.Module):
def __init__(self, *args, **kwargs):
super().__init__()
self.linear = torch.nn.Linear(10, 10, bias=True)
def forward(self, X):
X = self.linear(X)
return X
repeat_block = torch.nn.ModuleList([DummyRepeatBlock() for i in range(6)])
repeat_block
[344]:
ModuleList(
(0-5): 6 x DummyRepeatBlock(
(linear): Linear(in_features=10, out_features=10, bias=True)
)
)
[345]:
for params in repeat_block.parameters():
print(params.shape)
torch.Size([10, 10])
torch.Size([10])
torch.Size([10, 10])
torch.Size([10])
torch.Size([10, 10])
torch.Size([10])
torch.Size([10, 10])
torch.Size([10])
torch.Size([10, 10])
torch.Size([10])
torch.Size([10, 10])
torch.Size([10])
As I am repeating the block 6 times, It is visible that the learnable parameters are multiplied by 6.
Final Linear Layer and Softmax#
As transformer is
Document Completion,Next Word Prediction,AutoregressiveModel, we need a final layer that in essence provides us with next word probability.The last tokens dimentions (T = -1) probabilities(tensorflow)/logits(pytorch) will be selected to interpret next token.
In below example If the output is (Batch, Tokens, Vocab) dimensions tensor, then we need to pick the last token’s vocab probability
Token dim
_________________-1_
Batch /________________/_ /|
dim /________________/__ /| |
| | | | |
| | | | |
| | | | |
Vocab Dim| | | | |
| | | | |
| | | | |
| | | |/
|________________|__ |/